tiempo densidad
1 0 9.454942
2 2 17.661370
3 4 37.921560
4 6 57.995942
5 8 101.493323
6 10 200.220597
7 12 282.633370
8 14 354.657568
9 16 514.463729
10 18 660.897554
11 20 907.514490
12 22 913.596612
13 24 969.251741Modelado en R
B0305 – Lab Eco Gral
https://ucr-ecologia.github.io/B0305-lab-eco-gral/
01 Aug 2025
Visualizar los datos
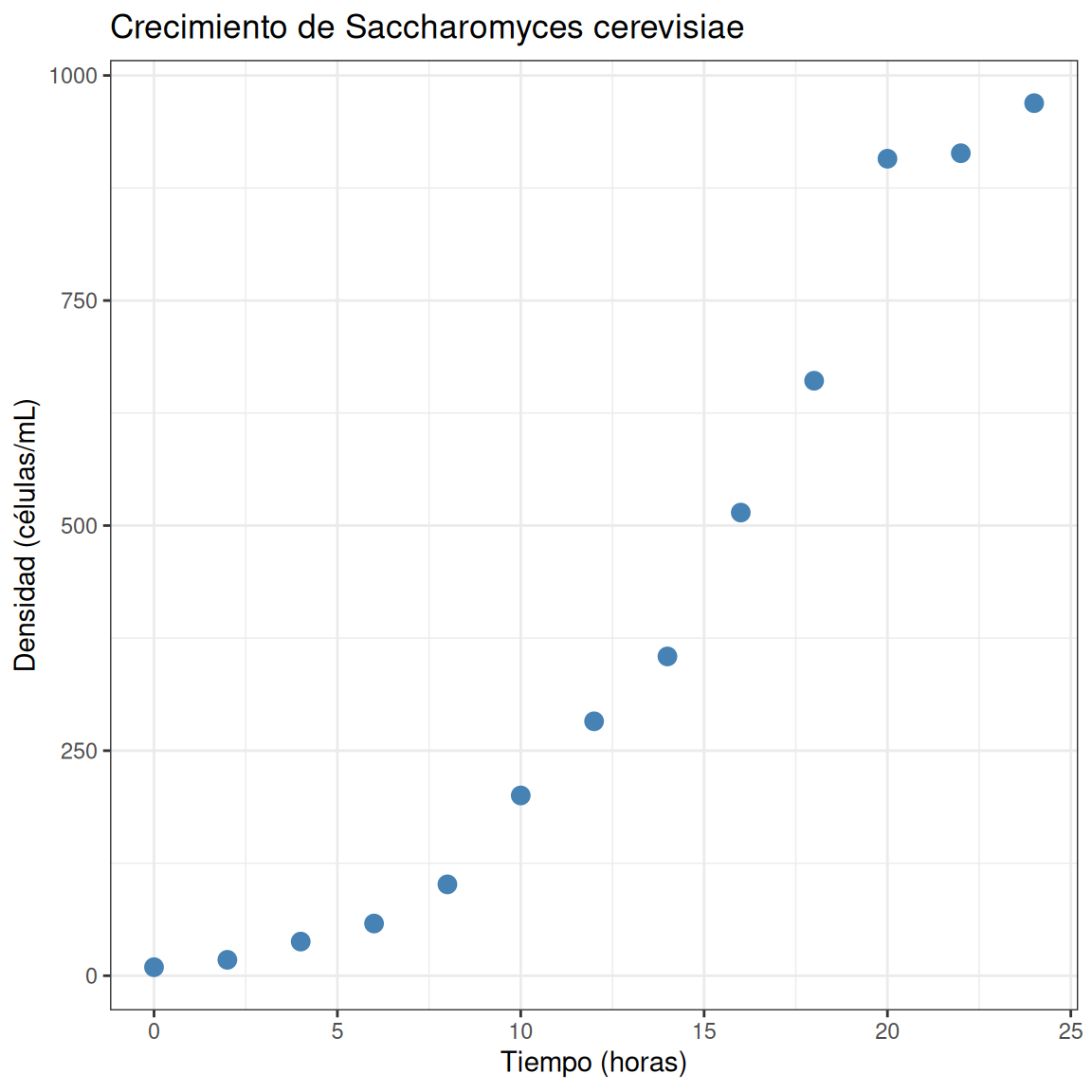
¿Qué patrón observas? ¿Cómo modelarías este crecimiento? 🤔
Visualizar el ajuste lineal
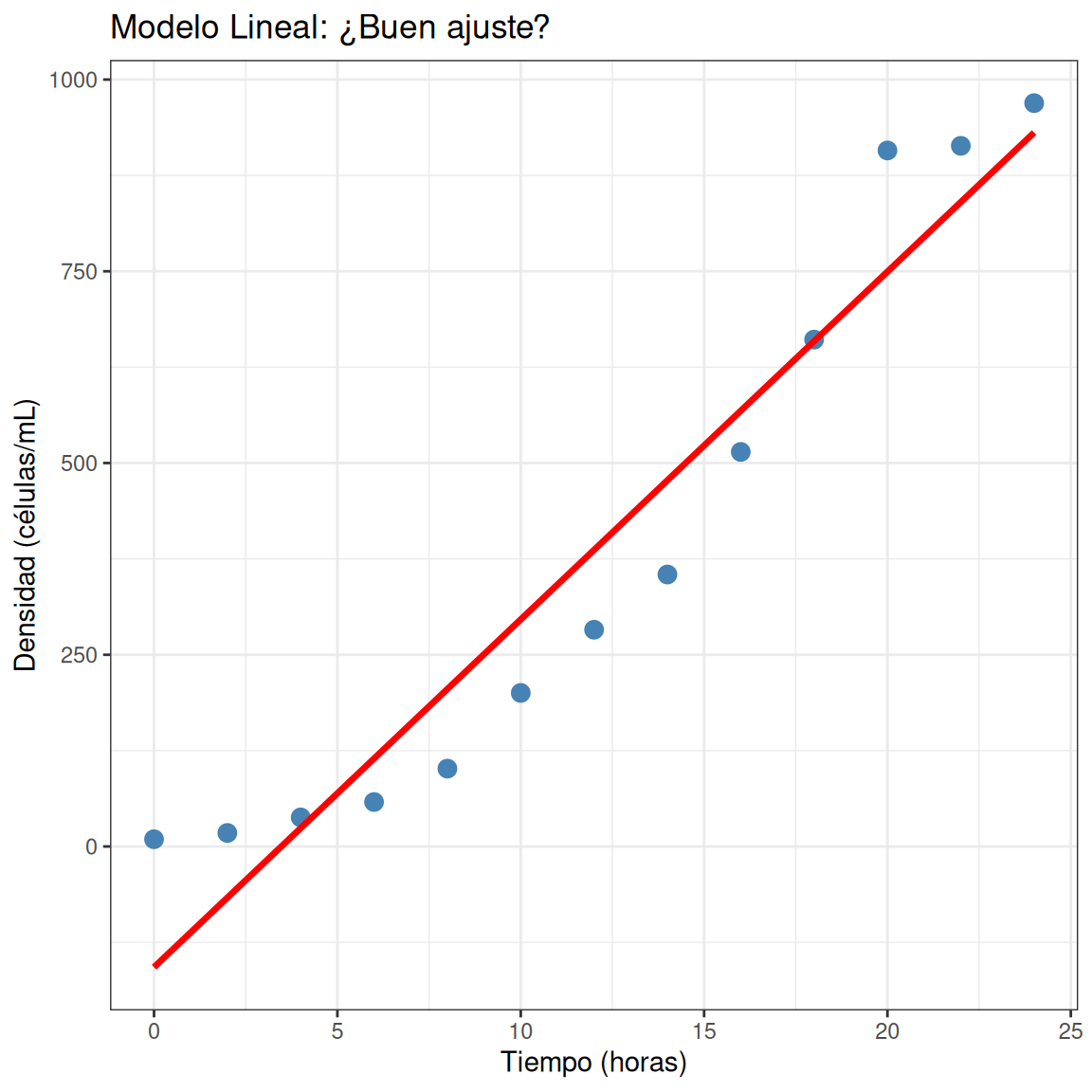
¿Qué problemas observas con este modelo? 🚨
Diagnósticos del modelo lineal
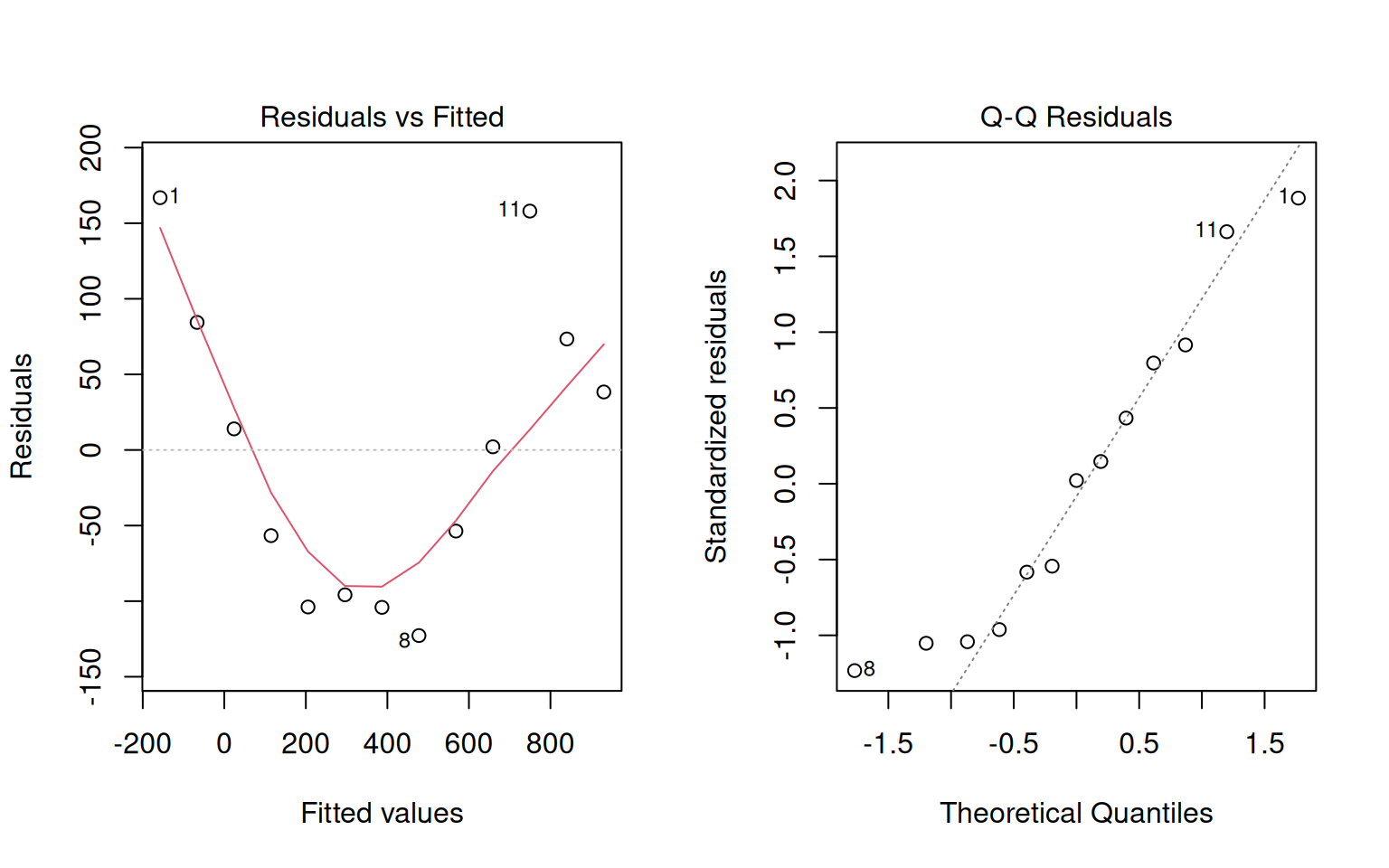
Problemas evidentes:
- Residuos no aleatorios (patrón curvo)
- Heteroscedasticidad (varianza no constante)
- ¡El modelo predice densidades negativas!
Visualizar en escala logarítmica
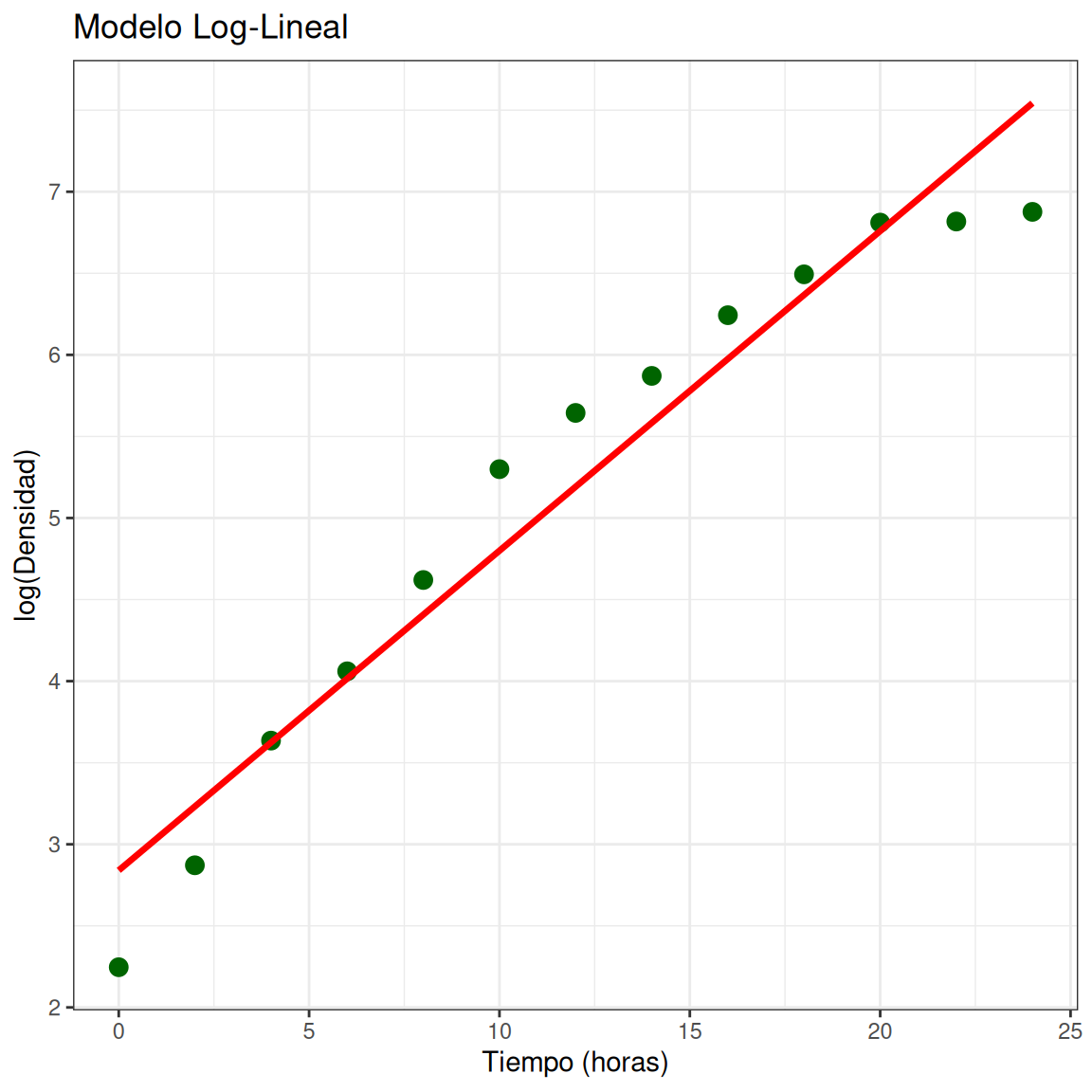
¿Mejor ajuste en los primeros puntos, pero qué pasa después? 🤔
Comparar modelos en escala original
# Predicciones del modelo log-lineal
levaduras$pred_log <- exp(predict(modelo_log))
p4 <- ggplot(levaduras, aes(x = tiempo, y = densidad)) +
geom_point(size = 3, color = "steelblue") +
geom_line(aes(y = pred_log), color = "darkgreen", size = 1.2) +
labs(x = "Tiempo (horas)",
y = "Densidad (células/mL)",
title = "Modelo Log-Lineal vs Datos Reales")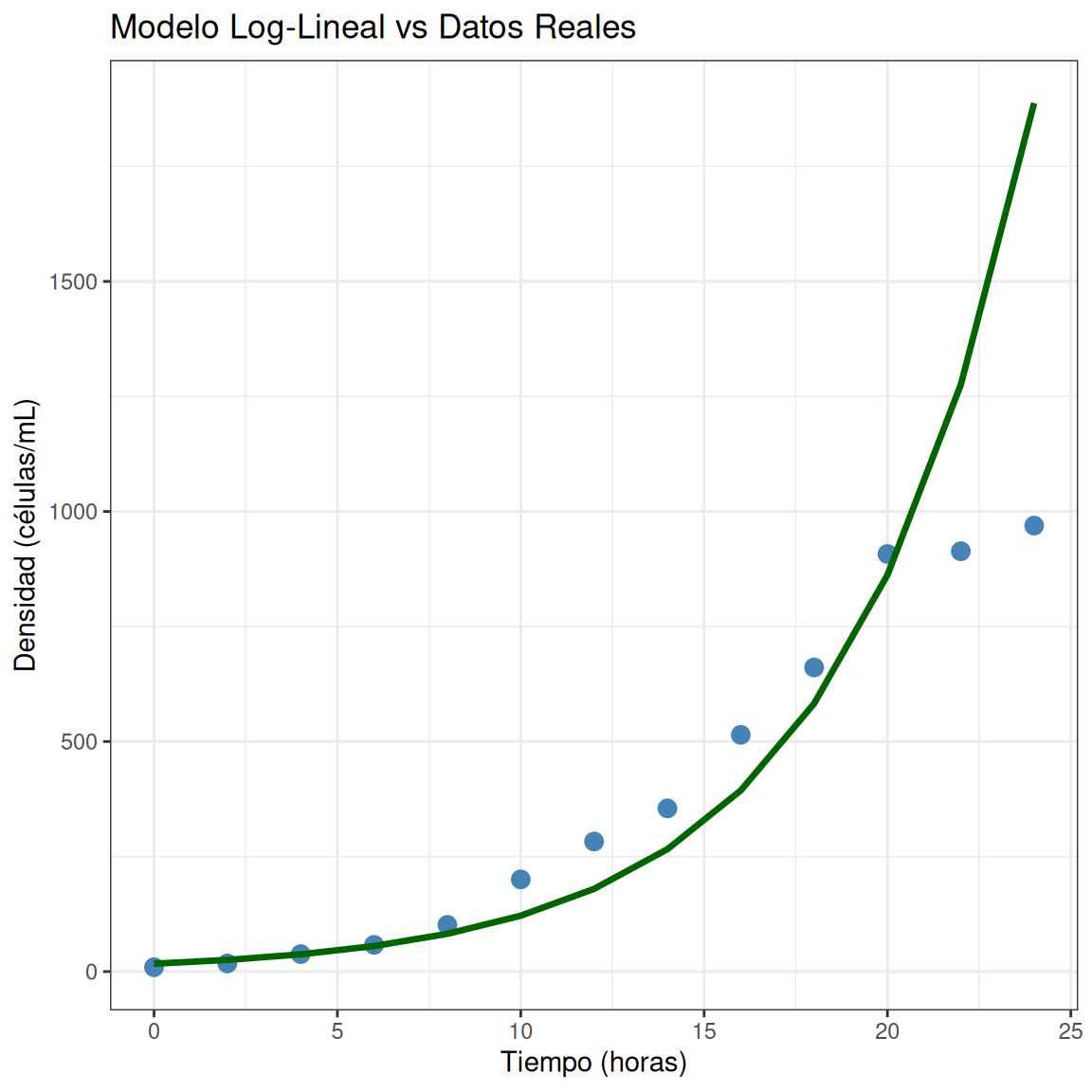
Problema: ¡Predice crecimiento exponencial infinito! 📈
Visualizar el modelo logístico
levaduras$pred_logistico <- predict(modelo_logistico)
p5 <- ggplot(levaduras, aes(x = tiempo, y = densidad)) +
geom_point(size = 3, color = "steelblue") +
geom_line(aes(y = pred_logistico), color = "purple", size = 1.2) +
labs(x = "Tiempo (horas)",
y = "Densidad (células/mL)",
title = "Modelo Logístico: ¡Ajuste Biológicamente Realista!")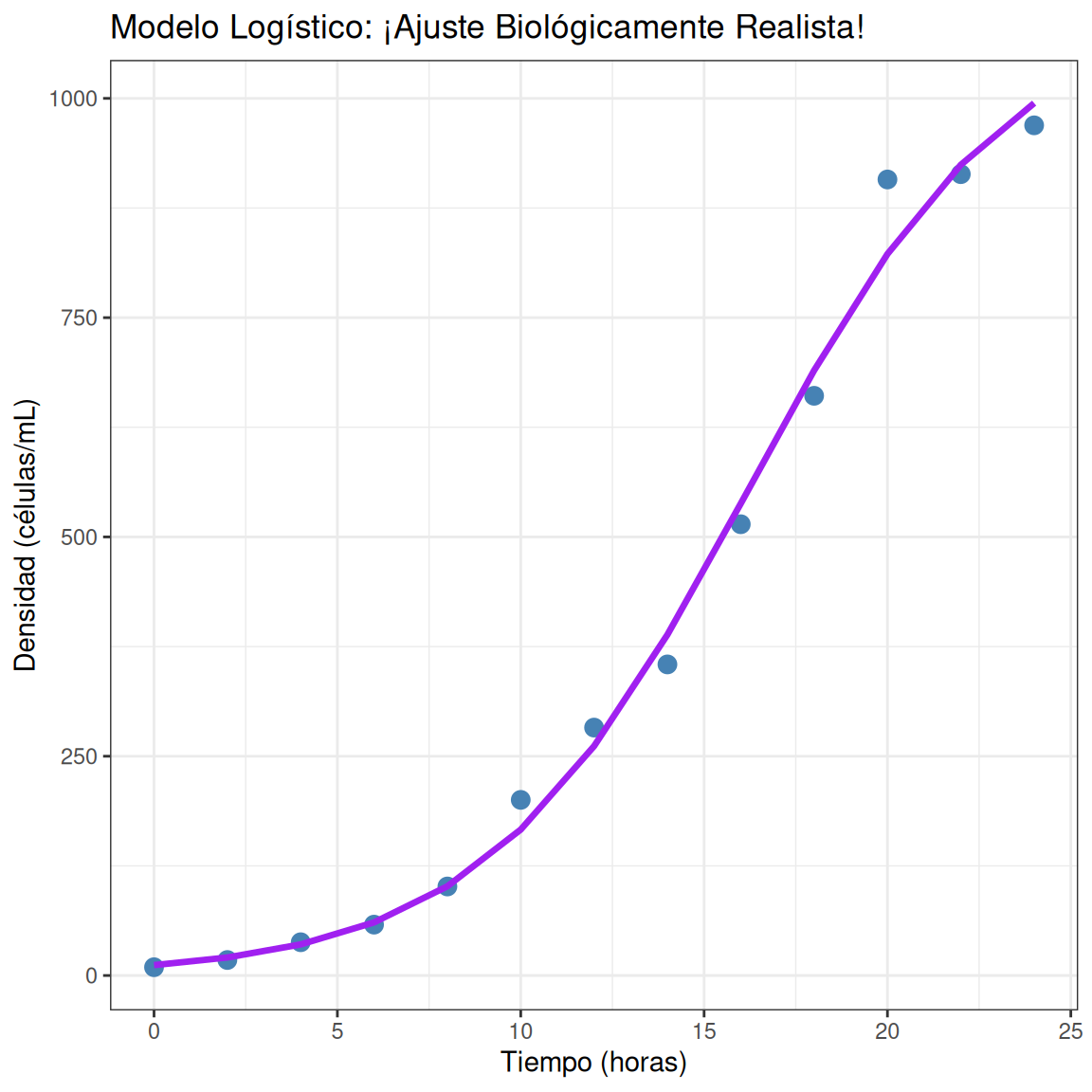
Comparación de los tres modelos
# Preparar datos para comparación
levaduras$pred_lineal <- predict(modelo_lineal)
levaduras$pred_logistico <- predict(modelo_logistico)
p6 <- ggplot(levaduras, aes(x = tiempo, y = densidad)) +
geom_point(size = 3, color = "steelblue") +
geom_line(aes(y = pred_lineal, color = "Lineal"),
size = 1) +
geom_line(aes(y = pred_log, color = "Log-lineal"),
size = 1) +
geom_line(aes(y = pred_logistico, color = "Logístico"),
size = 1) +
scale_color_manual(values = c("Lineal" = "red",
"Log-lineal" = "darkgreen",
"Logístico" = "purple")) +
labs(x = "Tiempo (horas)",
y = "Densidad (células/mL)",
title = "Comparación de Modelos",
color = "Modelo")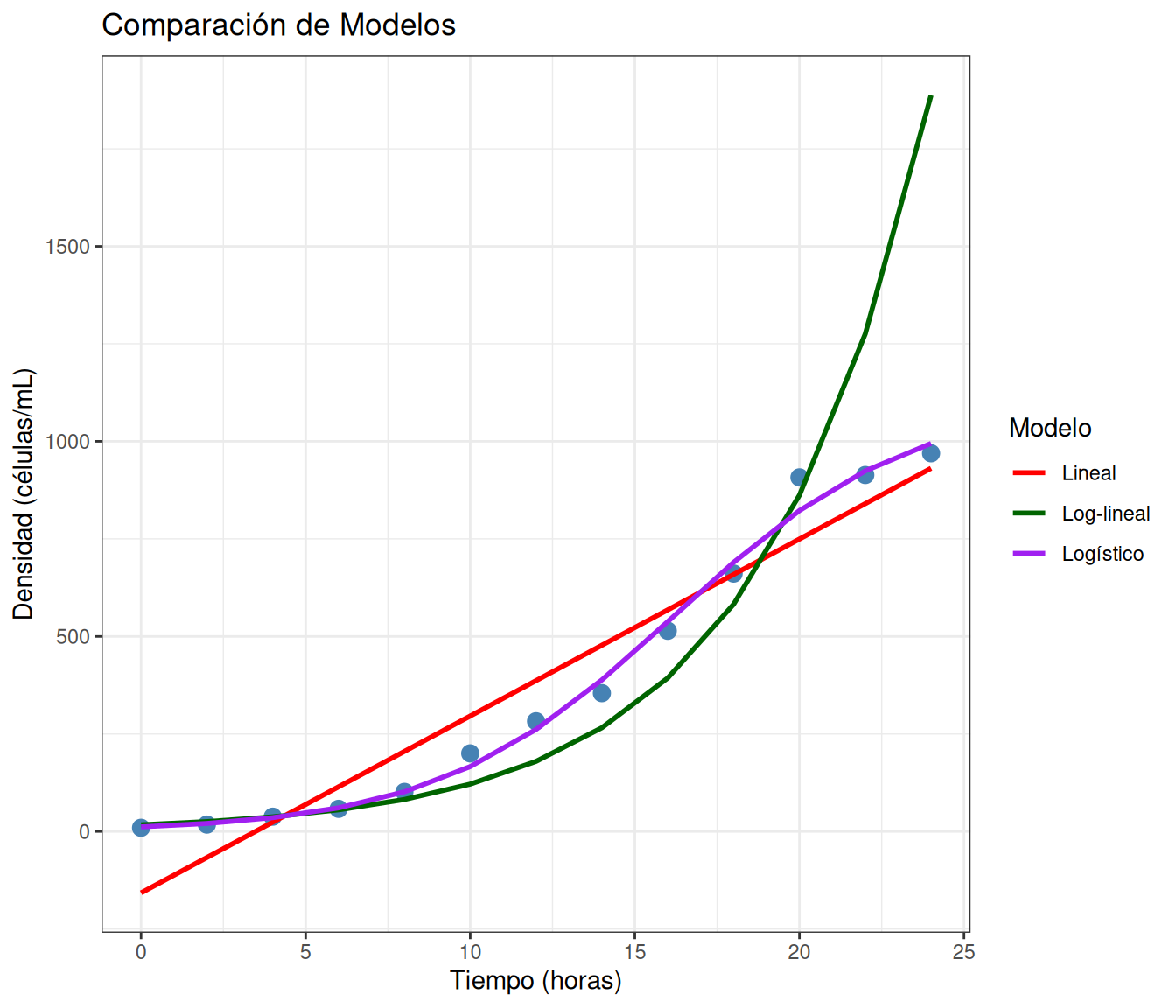
Análisis de residuos
# Crear data frame con residuos
residuos_df <- data.frame(
tiempo = rep(levaduras$tiempo, 3),
residuos = c(residuals(modelo_lineal),
residuals(modelo_log),
residuals(modelo_logistico)),
modelo = rep(c("Lineal", "Log-lineal", "Logístico"),
each = nrow(levaduras))
)
p7 <- ggplot(residuos_df) +
aes(x = tiempo, y = residuos, color = modelo) +
geom_point(size = 2) +
geom_hline(yintercept = 0, linetype = "dashed") +
facet_wrap(~modelo, scales = "free_y") +
labs(
x = "Tiempo (horas)",
y = "Residuos",
title = "Análisis de Residuos por Modelo") +
theme(legend.position = "bottom")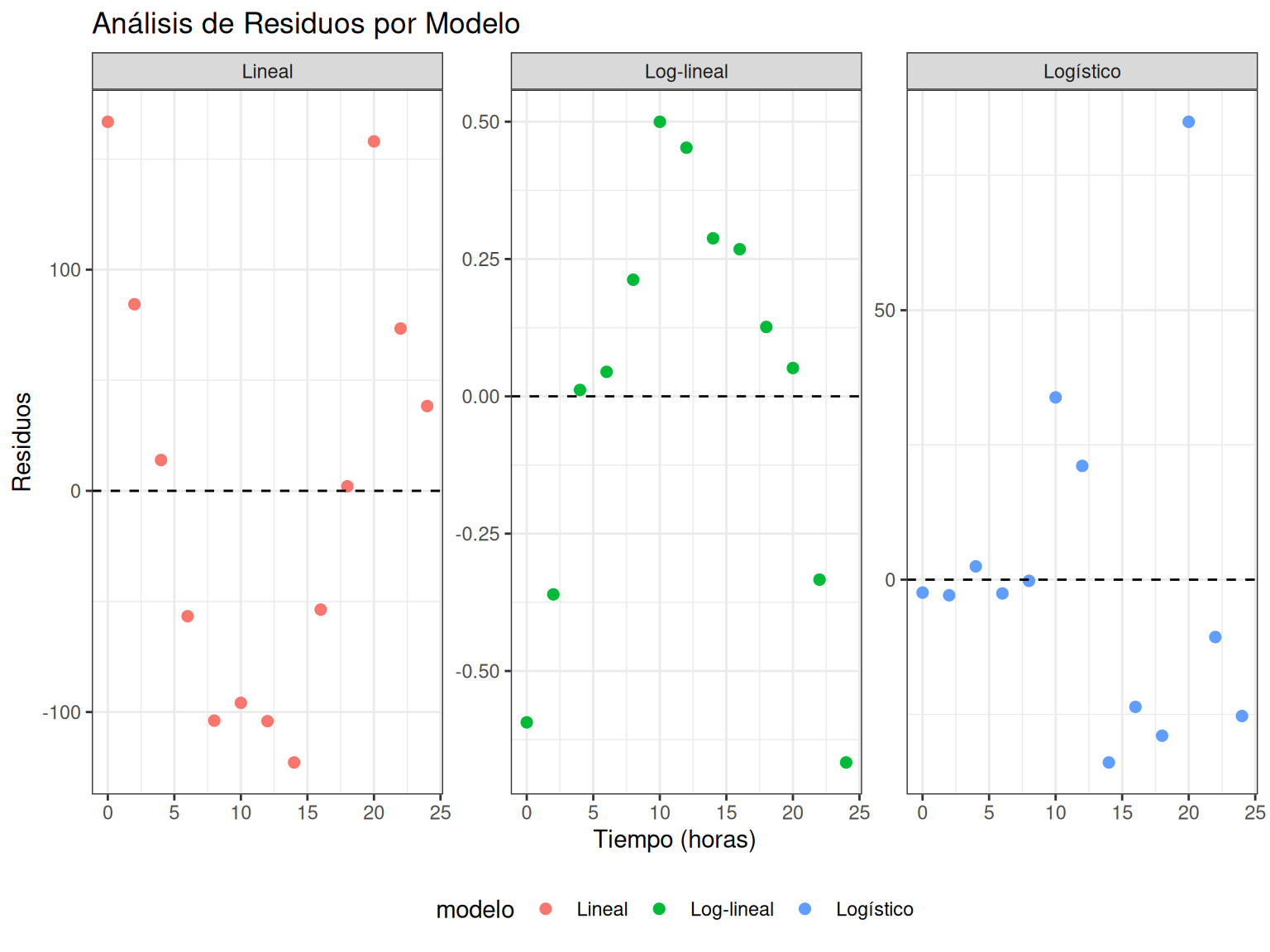
Residuos - Comparación visual
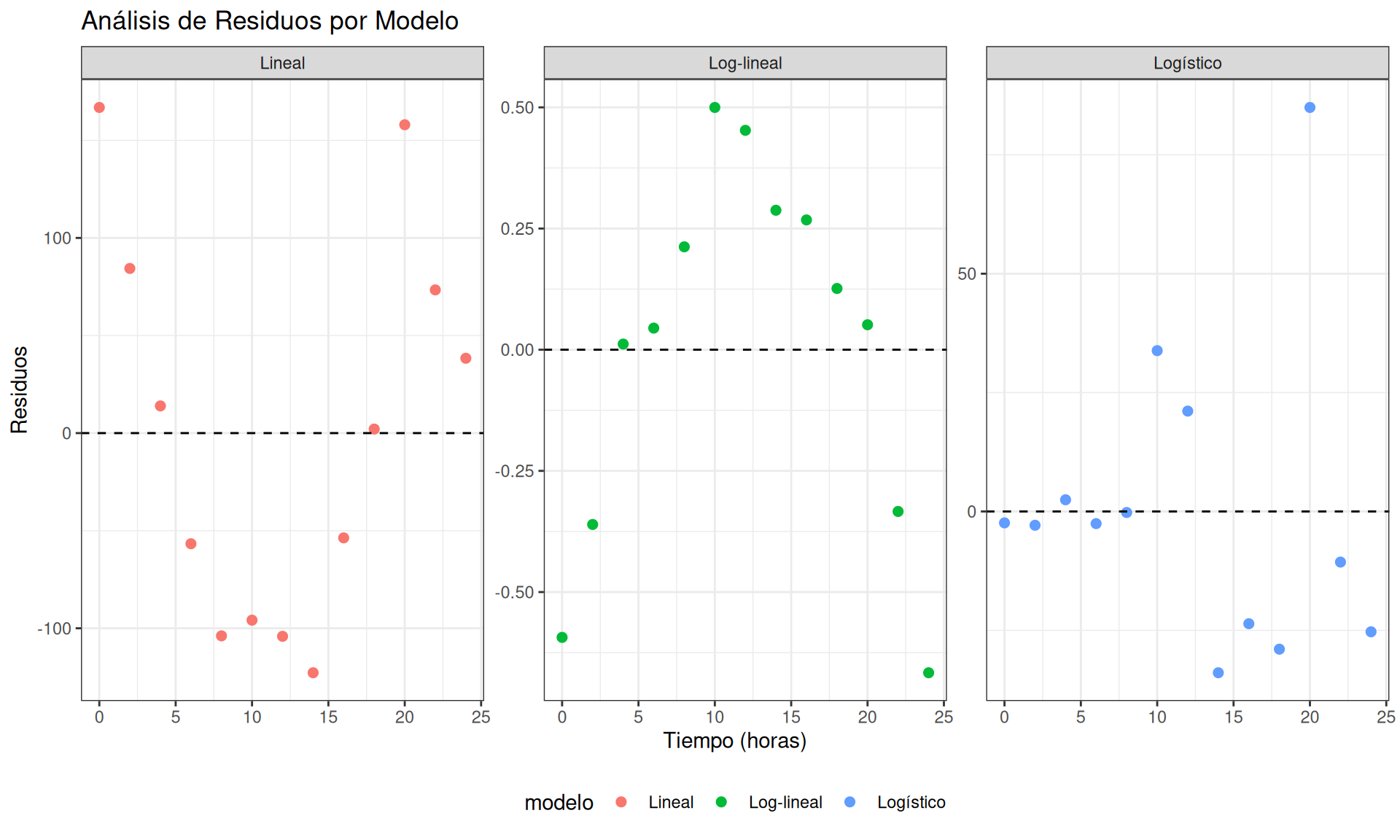
¿Qué modelo tiene los residuos más aleatorios? 🎯
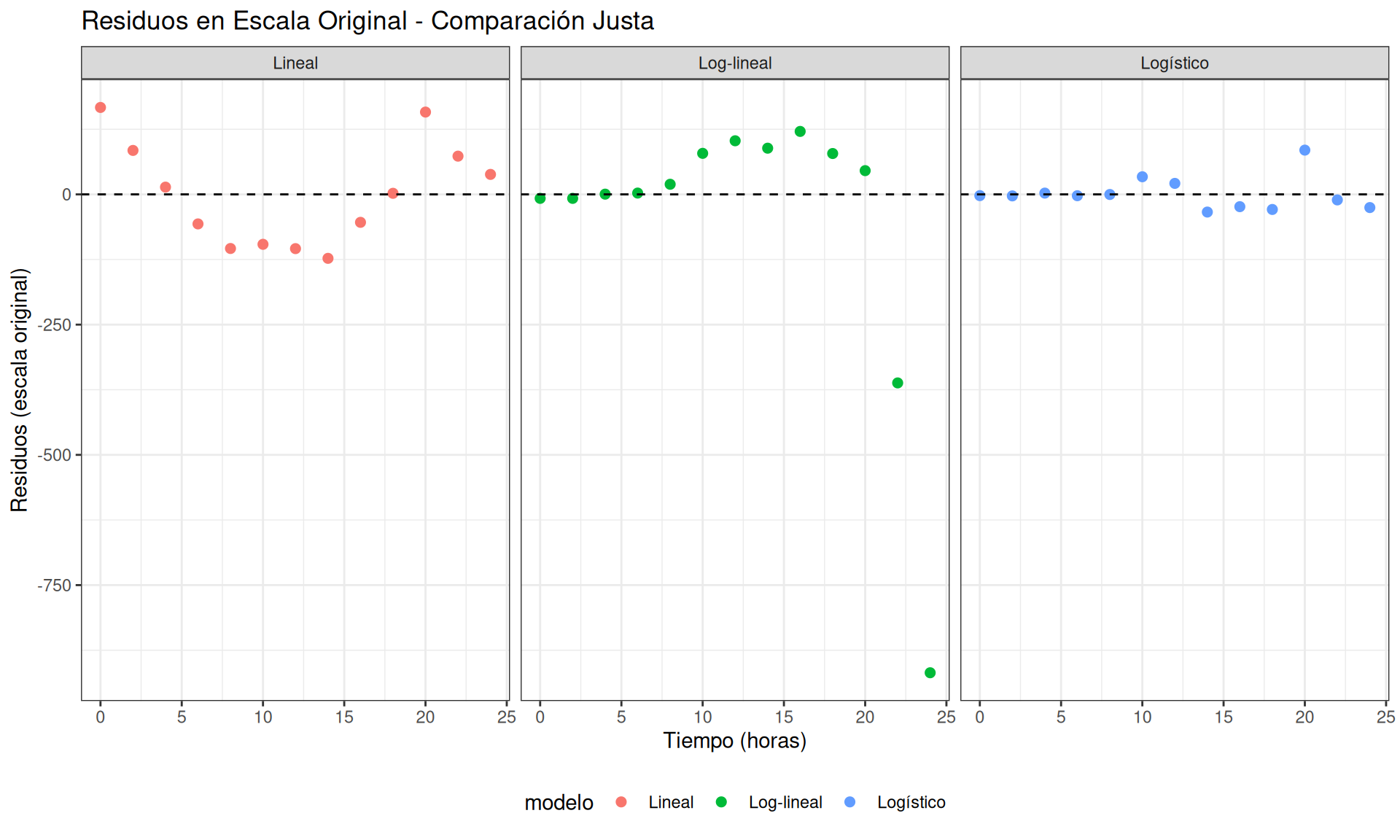
Residuos en escala original - Comparación visual
Ahora podemos ver cuál modelo realmente ajusta mejor 👀
# Crear data frame para visualización
residuos_originales_plot <- data.frame(
tiempo = rep(levaduras$tiempo, 3),
residuos = c(residuos_originales$lineal,
residuos_originales$log_lineal,
residuos_originales$logistico),
modelo = rep(c("Lineal", "Log-lineal", "Logístico"),
each = nrow(levaduras))
)
p8 <- ggplot(residuos_originales_plot) +
aes(x = tiempo, y = residuos, color = modelo) +
geom_point(size = 2) +
geom_hline(yintercept = 0, linetype = "dashed") +
facet_wrap(~modelo) +
labs(x = "Tiempo (horas)",
y = "Residuos (escala original)",
title = "Residuos en Escala Original - Comparación Justa"
) +
theme(legend.position = "bottom")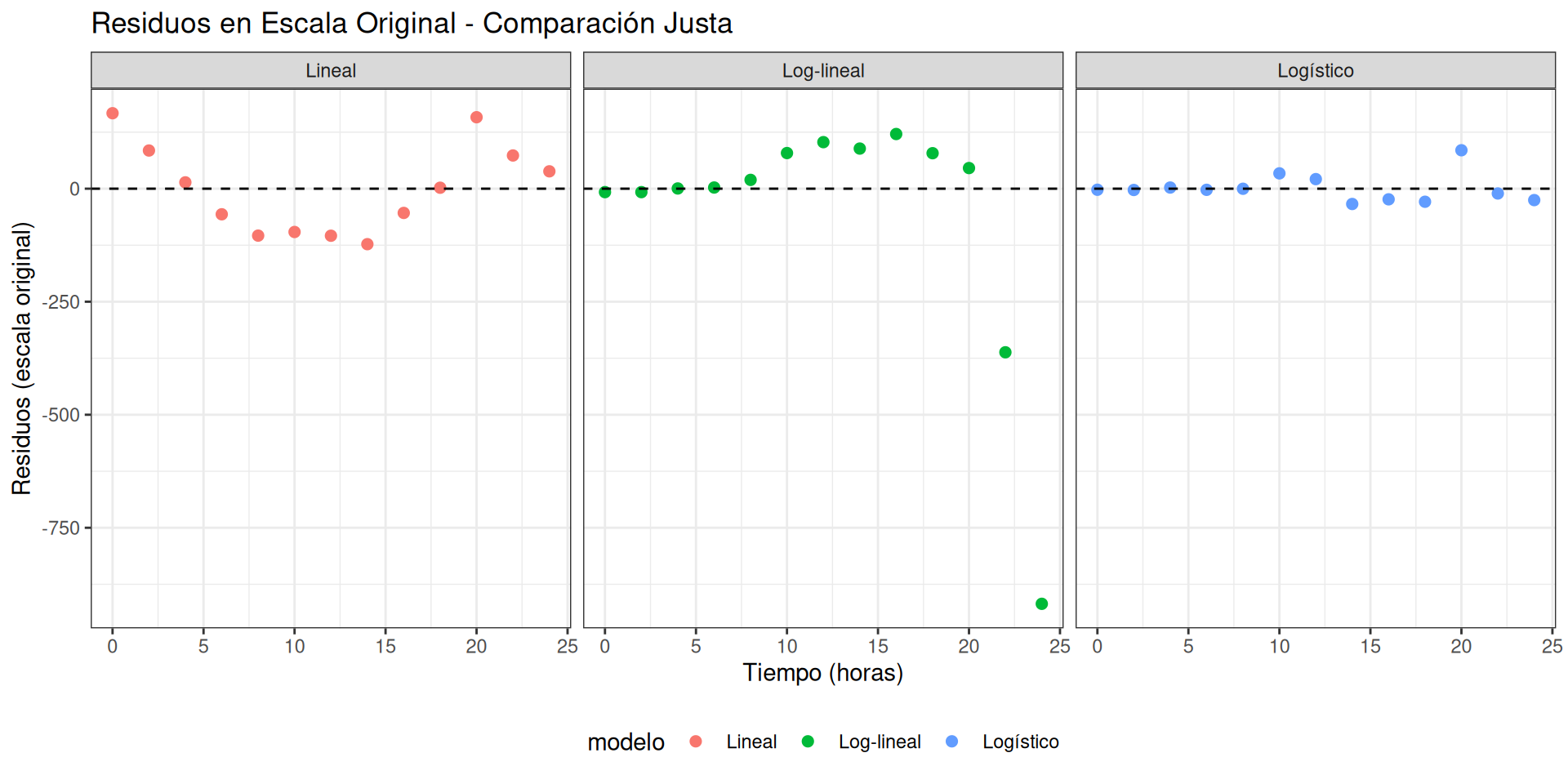
Residuos en escala original - Comparación visual